
Real-time Payments
,
Banking Infrastructure
by
Ramiro Danieli
A “real-time payment” is a transaction in which funds are made available to a recipient – and taken from a sender – almost immediately when a user clicks “send payment” on their mobile app. This process involves several distributed systems: the user’s mobile payment app, the payment network service, the banking core system, and two internal PortX services – UserExperience and PaymentSettlements. This article will share how we designed and implemented a highly reliable “Send Payment” distributed business transaction based on the saga pattern using Apache Camel and Apache Kafka.
Defining the “send payment” process
We began by summarizing the high-level steps of the “send payment” use case:
Create a new UserTransaction object on the UserExperience service that records when a user has initiated a payment.
Call the banking core system to transfer the customer funds to a settlement account; fail the transaction if the customer doesn’t have enough funds.
Send the payment to the payment network. Once the payment network accepts the payment, it is irrevocable. At that point, the process is committed to completing the actual funds transfer to the receiving bank.
Record on the PaymentSettlements service that a payment was sent to the Payments Network.
Update the User Transaction at the UserExperience service.
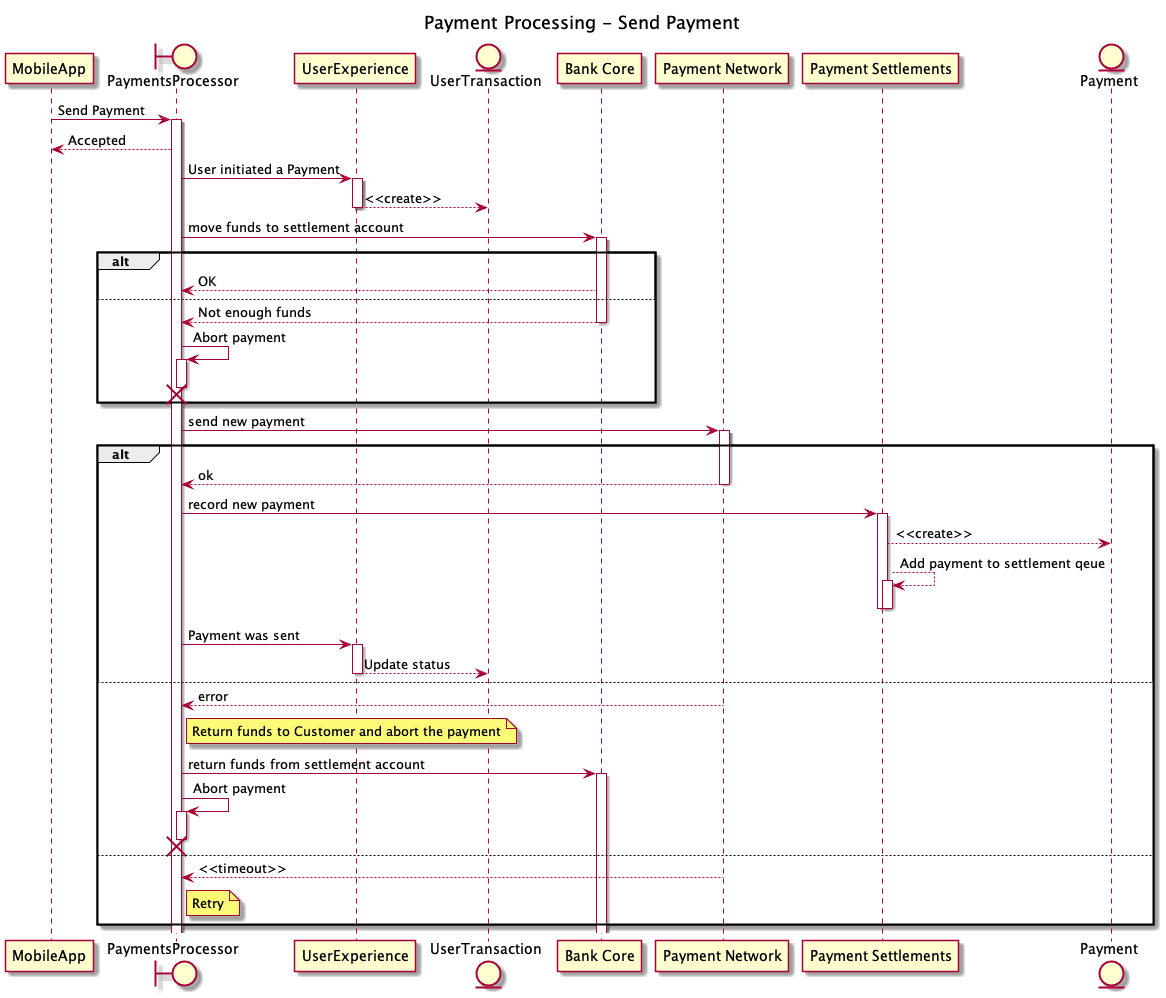
Diagram showing the interaction between the involved systems
Conceptually, these steps form a business transaction. It’s important that all of the steps are performed. Whether the process is successful or an error occurs, the system must remain in a consistent state. Otherwise, the process could result in some undesirable outcomes. For example, the process must ensure that:
If the payment can’t be sent through the payment network, funds are not held indefinitely.
If the payment is added to the payment network, funds are transferred to the receiving Bank.
Since the flow involves distributed services that are out of our control and microservices that possess their own storage, we can’t implement a distributed transaction using two-phase commit (2PC) or similar protocols that require the participants to apply a prepare-reserve/commit protocol with a centralized coordinator.
On the “happy path,” where all systems are online and there are no errors, the transaction will be processed very quickly, and the user will receive the confirmation immediately. However, if there is any network delay, resource problem, or any other error condition, the user must be informed that the transaction is in progress. The process will attempt to complete the step for an amount of time before it fails and is aborted.
In summary, this design:
Does not impose throughput or performance restrictions when the system is in its default working condition.
Avoids leaving the system in an inconsistent state when there is an error.
Enables us to correct errors that would otherwise result in an inconsistent state and incomplete transactions due to the distributed nature of the system. For example:
A call to a remote service times out, but the called system actually processed it.
The calling thread crashes or hangs while processing or before receiving the response.
Supports multiple processing instances (typical of a container-based application) to avoid single points of failure.
Why we chose the saga pattern
To design the solution, we followed the saga pattern that Héctor Garcia-Molina and Kenneth Salem created in 1987. They developed the pattern in the context of Long-Running Transactions to avoid holding database resources for an extended period of time1. For our use case, it allows us to implement the distributed business transaction, handle the error cases, and ensure that we can leave the system in an eventually consistent state. It does this by splitting a database transaction into two types of sub-transactions: atomic transactions and compensating transactions. The database will run these transactions if there is a need to rollback the whole process.
Atomic and retryable steps
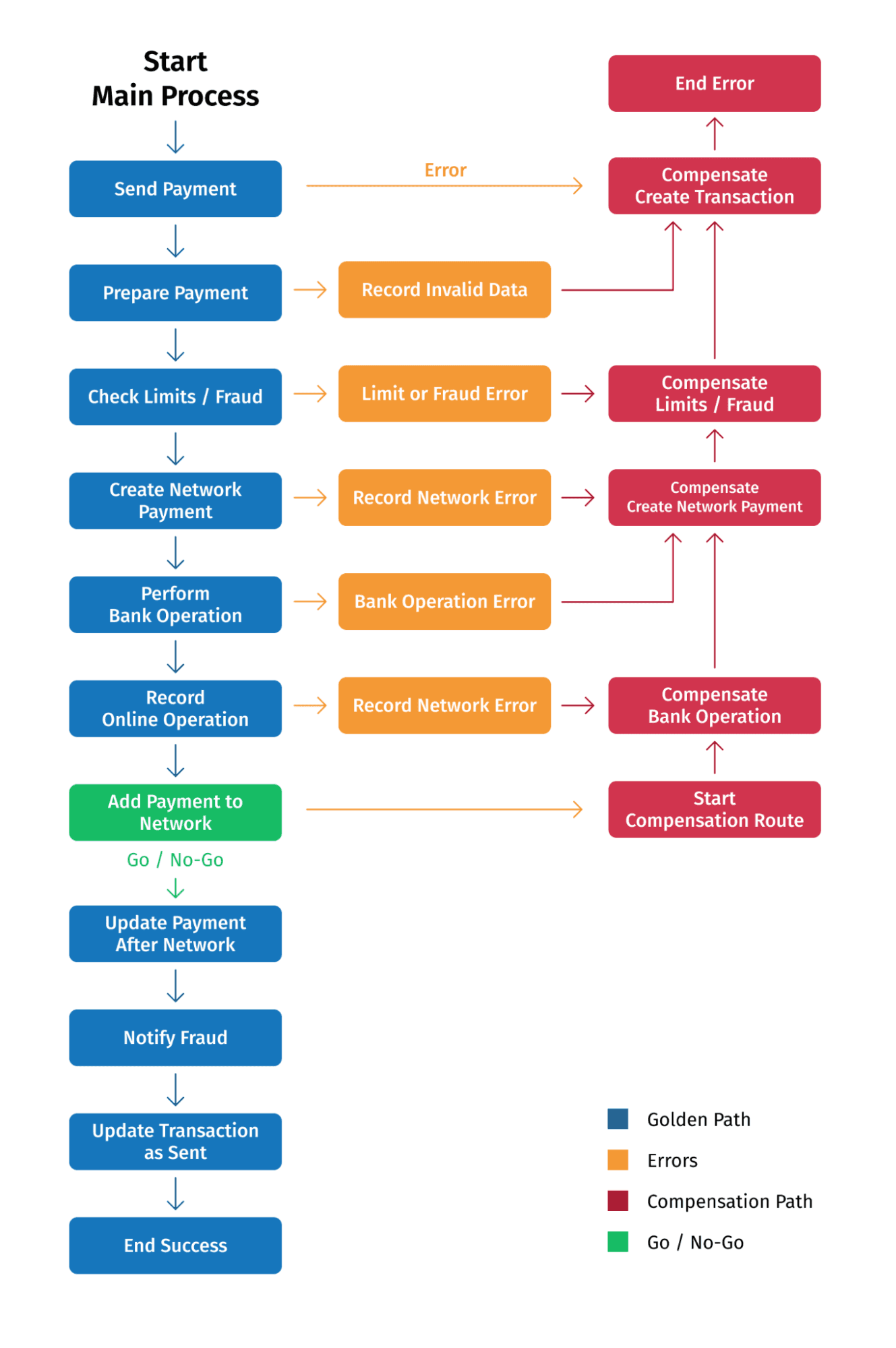
Diagram showing the main process and the compensate route
In a distributed microservices context where there is no central database providing the transactional capabilities, the saga pattern moves the transactional responsibility to the application. A saga consists of individual atomic steps requires the application to ensure that the business transaction as a whole is implemented atomically – either all steps are successfully executed or none of them are. As a result, the application must be able to handle errors that can occur on each step and perform compensating transactions (“rollback” or “undo”) on the preceding steps.
If required, steps can be retried if they fail due to a technical error, the executing process dies, or any other reason. Since steps can be retried, a called service must also support retries such as providing idempotent operations on its API. In our example, the banking core system provides a REST API with an idempotent withdraw operation that transfers funds from the customer account to a settlement account. Our microservices are already accounted for because they implement REST APIs with idempotent operations of their own. The Payment Network provides a SOAP WebService with an AddPayment operation that can be safely retried without side effects or generating a duplicate payment.
In our process, there is a go/no-go point that represents the “Add payment to the Payment Network” step. If that step succeeds, the process must progress forward to complete the subsequent steps and the payment cannot be canceled if there’s an error beyond that point. If the go/no-go step fails, the previous steps must be undone. These compensating actions are also atomic steps and will be retried until it is successful.
Dirty Reads
The saga pattern doesn’t provide a distributed isolated transaction, so the system’s intermediate states can become visible. We call these “dirty reads.” An example of a “dirty read” is when the customer is able to see that funds have been withdrawn from their account even if the payment has yet to be sent to the Payment Network. In the event that the user checks their account balance while the “send payment” operation attempts to retry several times, the payment will still appear – even if it eventually fails. Once the transaction completes, the system will remove the payment, and the account balance will be left unaltered.
Quick notes about our saga design
Today, the saga pattern is popular in literature on microservices. However, our implementation varies from most available content because our use case integrates external systems – not only our microservices. This means we are not able to shape the participants’ APIs.
Additionally, we follow the “Orchestrated” variant of the saga pattern, where the process is explicitly defined in one place, and services are unaware that they are participating in a saga. Instead, they provide an API that is consumed from different clients.
Implementing a saga using Camel and Kafka
Once we designed the process and solution using the saga pattern, we implemented it using our current stack of Apache Camel and Apache Kafka. There are three key aspects of a saga pattern implementation: 1) Implementing the steps in an atomic and retryable way, 2) Executing the saga steps, and 3) Keeping the saga state.
Implementation
We implemented the PaymentsProcessor as a Camel application. This application contains the state machine logic described above, where each step and its compensating action were implemented as Camel Routes. We used Apache Kafka as the Asynchronous Message Passing mechanism to connect the steps. In this method, once a step finishes, it produces a message on a Kafka topic that triggers the subsequent step. Each step definition is constructed of the triggering message, the route that implements the step logic, and the message that it produces to begin the next step.
Execution
Consuming a Kafka message is what moves the saga forward – a key aspect of the pattern implementation. If a step fails due to an unexpected error, or because the thread/process/container that is processing the message is terminated, the message will not be consumed. Another consumer will then (re)process it.
Keeping the saga state
The saga state is kept in Kafka. The Camel application doesn’t store the saga state in a database or other mechanism, it consumes from and produces messages to Kafka.
Discarded alternatives
If you want to implement a saga-based solution on a Camel application, you will likely come across the Camel Saga EIP in your research. This platform-provided solution would seem like a natural choice. However, we discarded this alternative because it adds a lot of complexity to the infrastructure and didn’t provide the reliability we needed for a financial-grade solution. This implementation requires the deployment of a Narayana LRA Coordinator that works as a saga coordinator, complicating the deploying, monitoring, and licensing aspects.
An alternative to the saga pattern is to use a reserve/confirm protocol like the Try-Cancel/Confirm (TCC) pattern. We discarded this option because it required a “resource reservation” model similar to that of 2PC. This requirement didn’t apply because there was already an API in place for the external services. Our preference was a design that emphasizes transactions as steps and performs explicit compensating actions if needed.
How to implement saga steps in Apache Camel
Each step is a Camel Route that consumes from a Kafka topic and performs logic, including calling external services. If it’s successful, it will push a message to a topic that signals the next step to be performed along with the required data. It will send another message to a “state” topic that represents the current saga state. In the event of an error, the step can push a message to trigger the compensate route again along with the required data, including the error description.
The saga’s current state is materialized by aggregating the messages that flow on the “state” topic. We used a ksqlDB instance to perform this operation with a simple stream and table definition using SQL.
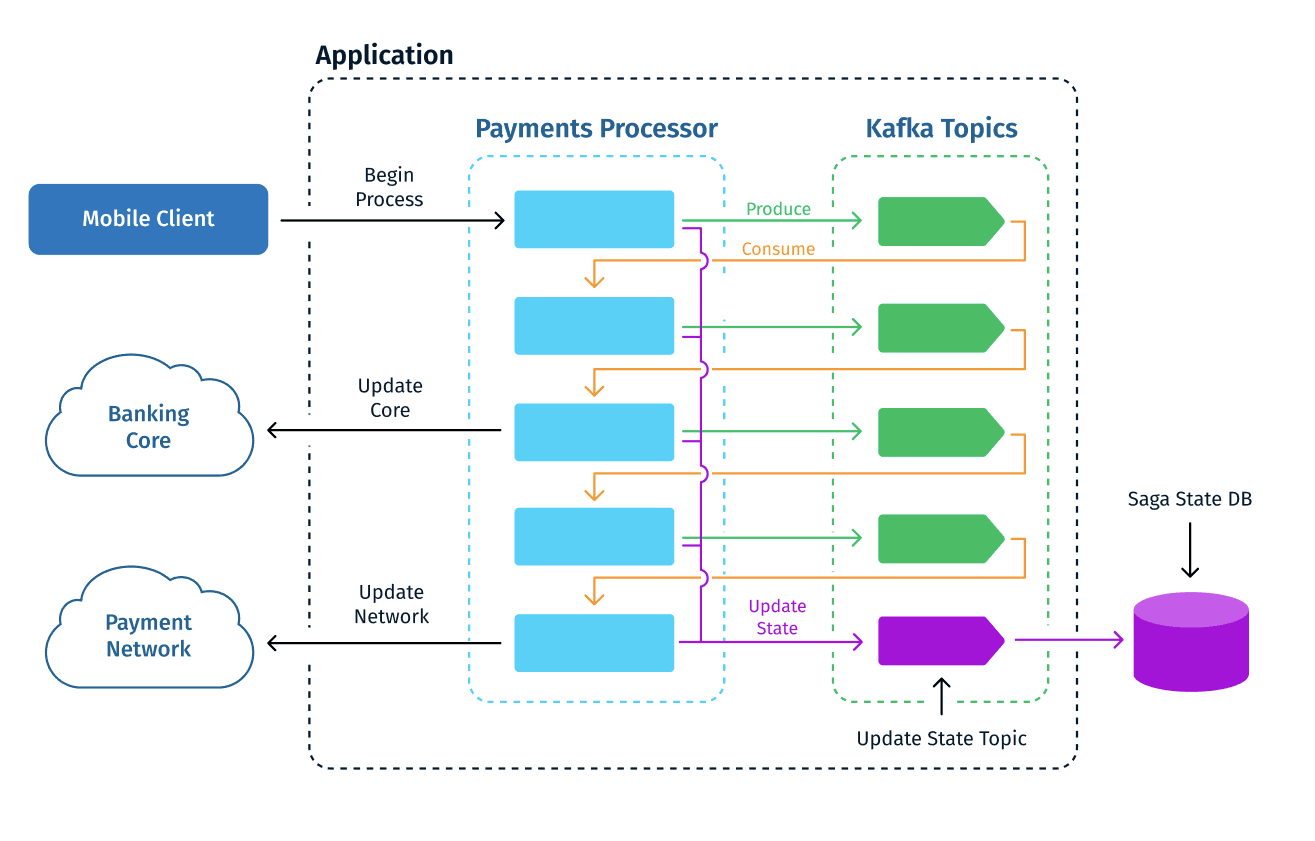
Diagram illustrating how the steps are connected through the Kafka topics, while their implementation is part of one application
We created a Camel library with a “builder” API that implements the common aspects of each step: consuming the Kafka topic, handling exceptions and retries, producing the next message, or triggering the compensate action.
To build a saga, create a new class that extends SagaRouteBuilder
To create the initial step of a saga, execute the following on the configure() method:
new StartSagaStepDefinition()
.sagaName(Constants.SEND_PAYMENT_SAGA_NAME)
.nextStep(Constants.PERFORM_BANK_OPERATION_STEP)
.startSagaRouteCreator(this::createStartSagaRouteDefinition)
.buildOn(this);
The createStartSagaRouteDefinition method handles the REST API POST /payments call that initiates the saga, sets the Exchange Message headers, and other specific logic.
Next, create and build a SagaStepDefinition object for each step. For example:
new SagaStepDefinition()
.sagaName(Constants.SEND_PAYMENT_SAGA_NAME)
.step(Constants.PERFORM_BANK_OPERATION_STEP)
.nextStep(Constants.ADD_PAYMENT_TO_NETWORK_STEP)
.stateAfterSuccess(Constants.BANK_OPERATION_PERFORMED_STATE)
.stepRouteBuilder(this::addPerformBankOperationStep)
.nextStepOnCompensatePath(Constants.UNDO_USER_TRANSACTION_STEP)
.compensateStepHandlerRouteBuilder(this::addCompensateBankOperationStep)
.buildOn(this);
The stepRouteBuilder implements the Camel route that handles the step-specific logic. It receives the payload from the previous step, performs any specific logic, decides which step is next, and adds the payload for the next step. In this example, the addPerformBankOperationStep method calls the Bank API to perform the funds movement operation.
Note: our example shows a linear flow to keep it simple. However, in our implementation, the state machine does have forks.
The saga library implements the Kafka consumer and producer and handles the exceptions to trigger retries or the compensating route as needed.
The steps implementation handles errors that occur and throws one of the following Exceptions provided by the saga library:
RetryForeverException: This is thrown by a step when a transient error occurs. The step will be retried indefinitely.
RetryableException: This is thrown by a step when a transient error occurs but may only require a limited amount of time or retries. The step will be retried following a step-specific configuration. If the error still happens, the saga is aborted.
AbortSagaException: The saga is aborted. If it is on the main path, the compensate path is initiated. If it is already on the compensate path, the message is published to a dead letter topic to be handled manually.
PoisonPillException: This occurs if the step receives a message that is invalid and is unable to start the compensating path because the saga is beyond its go/no-go point. The message is published to a dead letter topic handled manually because it could be related to a bug.
Apache Kafka-specific considerations
Strategy for Kafka consumer
Kafka messages are consumed (its offset committed) only after processing the message, including pushing the next message, to ensure that the system atomically and completely processes each step. If there’s any unexpected error, the message offset is not committed to avoid being lost and will is retried later. Thus, we use an “at-least-once” strategy.
Can “stuck” messages be avoided?
To keep the topics flowing, a consumer will commit the message offset unless there is an unexpected error, such as the consumer thread dying. In this case, the system reprocesses the message later. “Poison pills” will be handled by aborting the transaction and handling the poison pill as needed (moving them to a Dead Letter Topic). Note that this solution doesn’t account for bugs. If a bug causes a step not to consume a message, the topic will be stuck and can be located with a monitoring tool. The good news is that you won’t lose the message.
Can a step be processed twice?
We try to avoid pushing the same message twice by using idempotent producers. However, the steps should be implemented as if duplicates were possible. Conceptually, this is similar to a retry, so it should be accounted for already.
Topic/partition design
We use one topic per step following a naming convention like <subsystem>.<saga>.step.<step-name> and <subsystem>.<saga>.compensate.<step-name>, partitioned by sagaId. We chose the topic-per-step alternative to avoid slow throughput in the event a step fails repeatedly. Since each step pulls a message and then attempts to perform the actions by calling remote services (those actions may take a long time since they’re remote and may involve timeouts and retries), we risk blocking the whole saga if one saga step blocks because a service is down. Separate consumers per saga steps allow all steps to be processed concurrently.
Process visibility
We also use Kafka to store the saga state. After each step logic is complete, the saga processor produces a message to a Kafka topic to signal the next event (as described above) and to another topic called <subsystem>.<saga>.state that records the new saga state. A ksqlDB table materializes the current state by selecting the last state published. A monitoring component can use this table to get information about the current and previous state of a saga.
Start a conversation
Using the saga pattern to model our business transactions, we were able to implement a failure management pattern that is easy to understand and provides the reliability we need. With Camel, we created a library that implements the common aspects and focuses on the business process logic. Finally, Apache Kafka allowed us to store the saga state in a durable form and use stream processing tools like ksqlDB to synthesize the saga process state.
If you would like to learn more about our saga implementation, don’t hesitate to contact a member of our product team today or leave a comment below.
https://www.cs.cornell.edu/andru/cs711/2002fa/reading/sagas.pdf




1.833.667.6789
hello@portx.io




